


Recommendations are a game - a dangerous game (for us).
Recommendations are a game - a dangerous game (for us).
Machine-recommendation system ethics, models of human reward, reinforcement learning framing; followup on GPT-3.

This week we are discussing recommender systems. What began with an essay titled “On the ethics of recommendation systems” now encompasses a brief intro to recommendation systems online, ethics of such systems, ways we can formulate human reward, and views of human recommendations as a slowly updated batch reinforcement learning problem (the game, where our reward is not even in the loop).
A brief overview of recommender systems
The news feed systems, so to say. The recommender systems (Wikipedia had the most to the point summary for me) decide what content to give us, which is a function of our profile data and our past interactions. The interactions can include many things depending on the interface (mobile vs desktop) and platform (app, operative system, webpage). Netflix, often touted as making the most advancements to the technology, has a webpage describing some of their research in the area.
What kind of machine learning do these systems use? A survey from 2015 found that many applications used decision trees and Bayesian methods (because they give you interpretability). Only 2 years later there was a survey on exclusively deep learning approaches. I think many companies are using neural networks and are okay with the tradeoff of dramatically improved performance at the cost of interpretability - it’s not like they would tell the customer why they’re seeing certain content, would they?
I drew up a fun diagram that is your baseline, and it’ll be expanded throughout the article. It’s a sort of incomplete reinforcement learning framework of the agent takes action a -> environment moves to state s -> returns reward r.
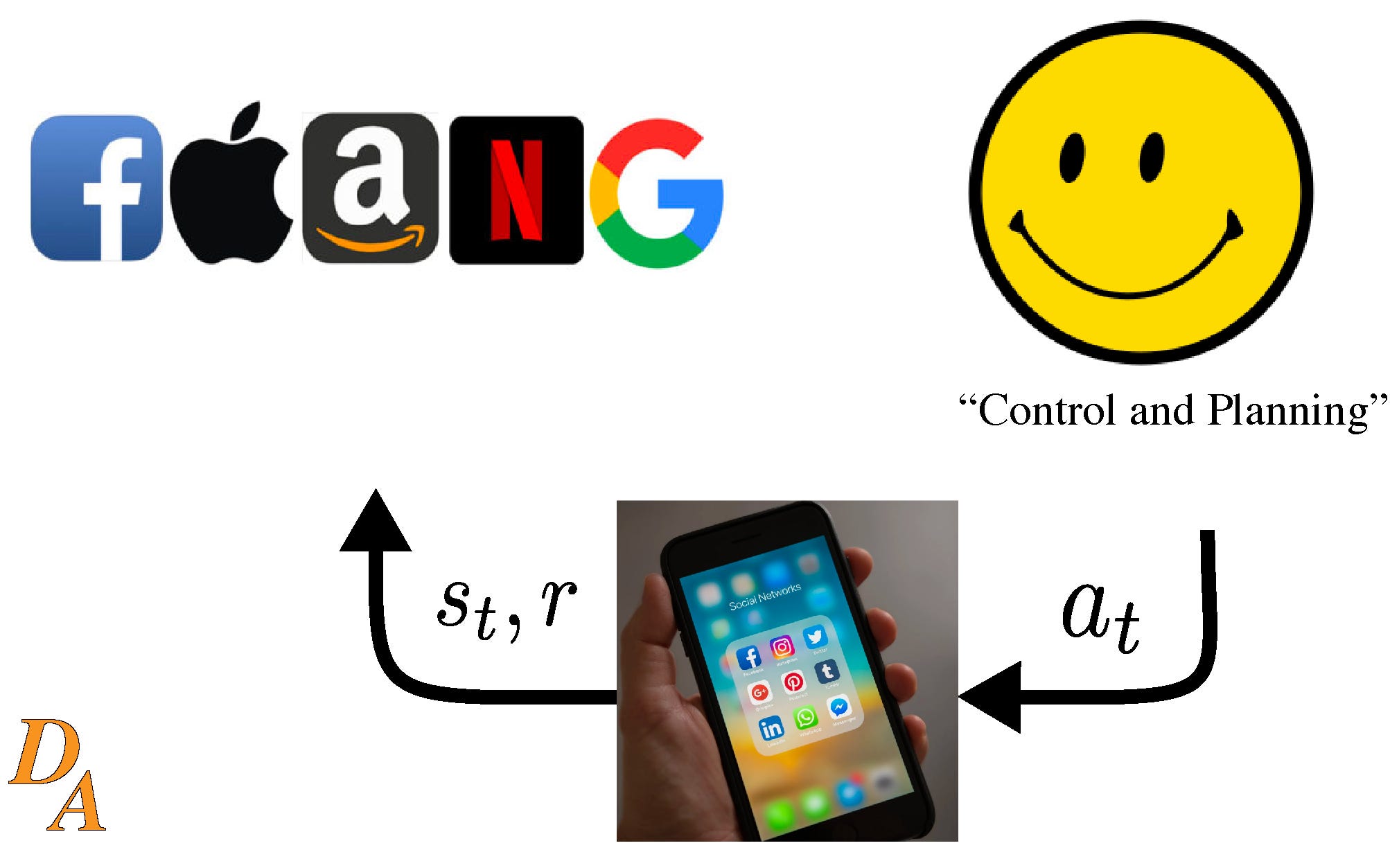
Clickthrough led to clickbait
Clickthrough (a heuristic of engagement, reward) was an early metric used to create recommendations. The clickbait problem (open link, close it immediately) led to a dwell time metrics on pages. I have been satisfactory burnt out of clickbait sites, so I started this direct-to-reader blog. That’s just the surface level effect for me, and I am sure there’s more. At one point, Facebook’s go-to metric for a while was the usage of the click to share button - okay, you get the point, on to the paper.
I found a paper from a workshop on Participatory Approaches to Machine Learning (when you look closer, there are many great papers to draw on, I will likely revisit) at the International Conference on Machine Learning last week. When you see block quotes, they are from What are you optimizing for? Aligning Recommender Systems with Human Values, Stray et. al, 2020. There’s some great context on how the systems are used and deployed.
Most large production systems today (including Flipboard (Cora, 2017) and Facebook (Peysakhovich & Hendrix, 2016)) instead train classifiers on human-labelled clickbait and use them to measure and decrease the prevalence of clickbait within the system.
Human labeled content is a bottleneck when generated content outpaces labeling capacity. Also, labeling a classifier will be outdated immediately at deployment (constantly moving test set). There are also companies that won’t describe how they operate. Another point regarding industry usage I found interesting is:
Spotify is notable for elaborating on the fairness and diversity issues faced by a music platform. Their recommendation system is essentially a two-sided market, since artists must be matched with users in a way that satisfies both, or neither will stay on the platform.
And, obvious comment below, but requisite.
Especially when filtering social media and news content, recommenders are key mediators in public discussion. Twitter has attempted to create “healthy conversation” metrics with the goal to “provide positive incentives for encouraging more constructive conversation” (Wagner, 2019).
My impression of the learned models is: If the big companies do it, it’s because it works. Again, don’t assume malintent, assume profits. Now that we have covered how the companies are using their platforms to addict us to their advertisements, here is a small update to our model - a feedback loop and bidirectional arrows.
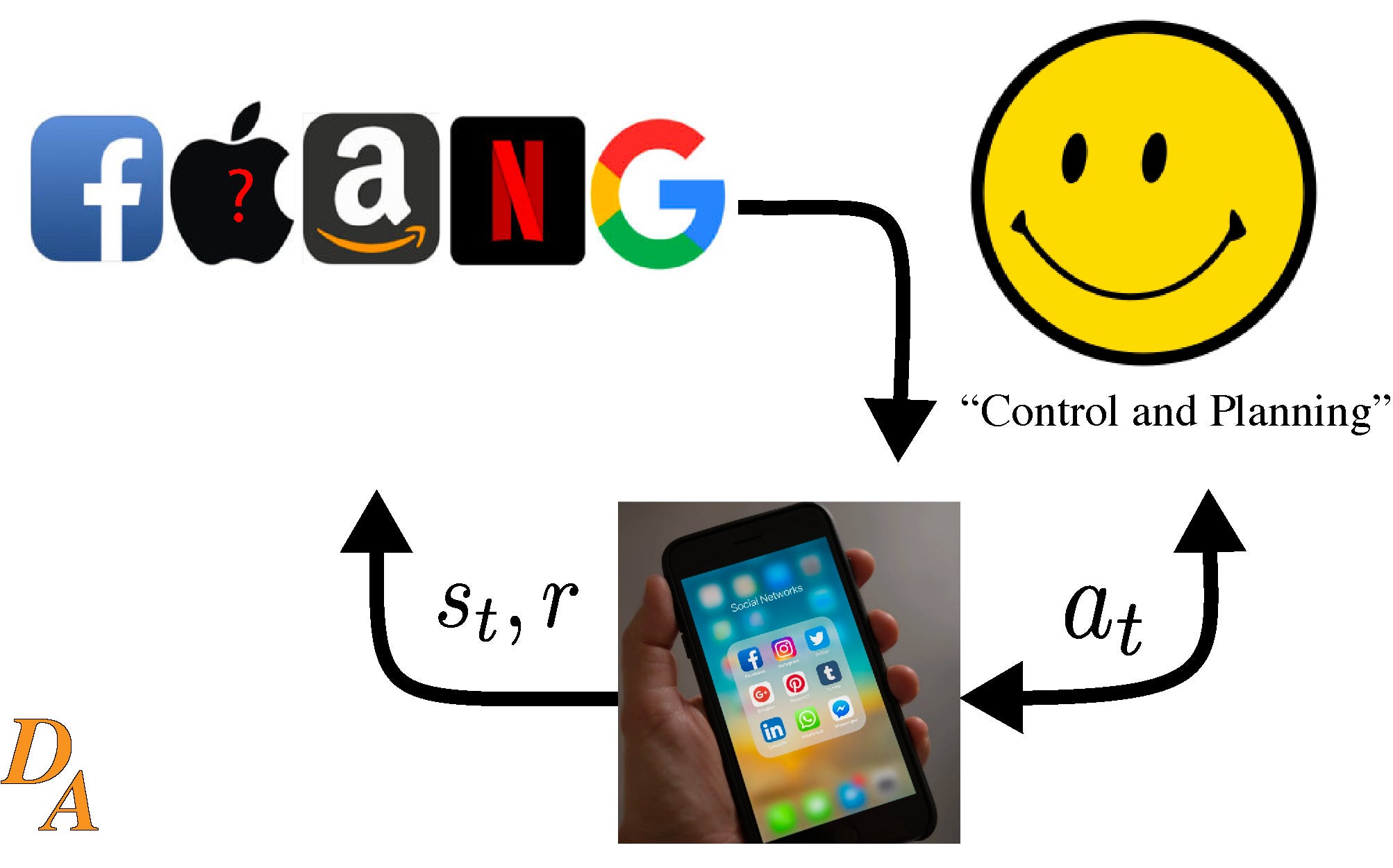
Ethics of Recommender Systems
Our computers are deciding what to put in front of us, primarily so that the companies retain us as reliable customers. What could go wrong? What are you okay with robots recommending for you? Your social media content - okay. How I decide my career path - I don’t know.
I don’t blame companies for making these tools and putting them in front of us - they want to make money after all. These issues will come to the forefront as the negative effects compound over the next few years. Here are a few points where I don’t think companies are held to high enough standards:
Financial Technology (Fintech) Companies: manipulate your brain into engaging with financial products in different ways, which has had more dramatic effects on people without certain financial stability.
High-traffic Media Platforms: Beyond the simple point of the hours you spend online each day, or how Google dictates everything you see, technology companies have tried to “be the internet” in developing nations. Click the link to see what happened when Facebook tried to be the internet in India (they were nice enough to include Wikipedia, though!).
News Sources: Mainstream newsrooms (and definitely fringe sites, and everything in between) use automated methods to tune what news is given to you. I see a future where they tune the writing style to better match your views, too. Conformism is not progressive.
I want to start with what has been called the Value Alignment Problem in at-scale, human-facing AI (example paper on legal contracts, AI, and value alignment Hadfield-Menell & Hadfield, 2019).
Low-level ethics of working with human subjects
I define the ethical problem here as short term results (highlighted below) and long term mental-rewiring of humans whose lives are run by algorithms.
Concerns about recommender systems include the promotion of disinformation (Stocker, 2019), discriminatory or otherwise unfair results (Barocas et al., 2019), addictive behavior (Hasan et al., 2018)(Andreassen, 2015), insufficient diversity of content (Castells et al., 2015), and the balkanization of public discourse and resulting political polarization (Benkler et al., 2018).
Stray et. al, 2020 continue and introduce the Recommender Alignment Problem. It is a specific version of the value alignment problem that could have increased emergence because of the prevalence of the technologies in our lives. If at this point you aren’t thinking about how they affect you, have you been reading closely? Finally, a three-phase approach to alignment:
We observe a common three phase approach to alignment: 1) relevant categories of content (e.g., clickbait) are identified; 2) these categories are operationalized as evolving labeled datasets; and 3) models trained off this data are used to adjust the system recommendations
This can be summarized as identification (of content and issues), operalization (of models and data), adjustment of deployment. This sounds relatively close to how machine learning models are deployed to start with, but it is detailed below.
High-level, recommender system adjustments:
The high-level ideas again are from the paper, but the comments are my own.
Useful definitions and measures of alignment - companies need to create research on internet metrics that better match user expectations and accumulated harm (or uplifting!)
Participatory recommenders - having humans in the loop for content will enable much better matching of human reward to modeled reward, which long term will pay off.
Interactive value learning - this is the most important issue and it can encompass all others. Ultimately, assume the reward function is a distribution and extreme exploitation dramatically decreases (more below)
Design around informed, deliberative judgment - this seems obvious to me, but please no fake news.
Let’s continue with point three.
Modeling human reward
The interaction between what the optimization problem is defined as and what the optimization problem really is is the long term battle of applying machine learning systems in safe interactions with humans.
The model used by most machine learning tools now is to optimize a reward function given to the computer by a human. The Standard Model (Russell - Human Compatible, 2019) is nothing more than an optimization problem where the outcomes will improve when the metric on a certain reward function is improved. This falls flat on its face when we consider comparing weighing reward of multiple humans (magnitude and direction), that AIs will exploit unmentioned avenues for action (I tell the robot I want coffee, but the nearest coffee shop is $12, that’s not an outcome I wanted, but it “did it”), and more deleterious unmodeled effects.
What is a better way to do this? The better way is again, interactive value learning. Value learning is a framework that would allow the AIs we make to never assume they have a full model for what humans want. If an AI only thinks that it will have a 80% chance of acting correctly, it will be much timider in its actions to maintain high expected utility (I think about the 20% chance including some very negative outcomes). Recommender systems need to account for this as well, otherwise, we will be spiraling in a game that we have little control over.
Reinforcement Learning with Humans and Computers in the Loop
Reinforcement learning is an iterative framework where an agent interacts with an environment via actions to maximize reward. Reinforcement learning (RL) has had a lot of success with confined games. In this case, there are two ‘game’ framings.
The application is the agent, and the human is part of the state space (actually fits with the problem formulation better)
The human is the agent, the computer, and the world is the environment, and the reward is hard to model. This one is much more compelling, so on I go. This is the game I refer to in my title.
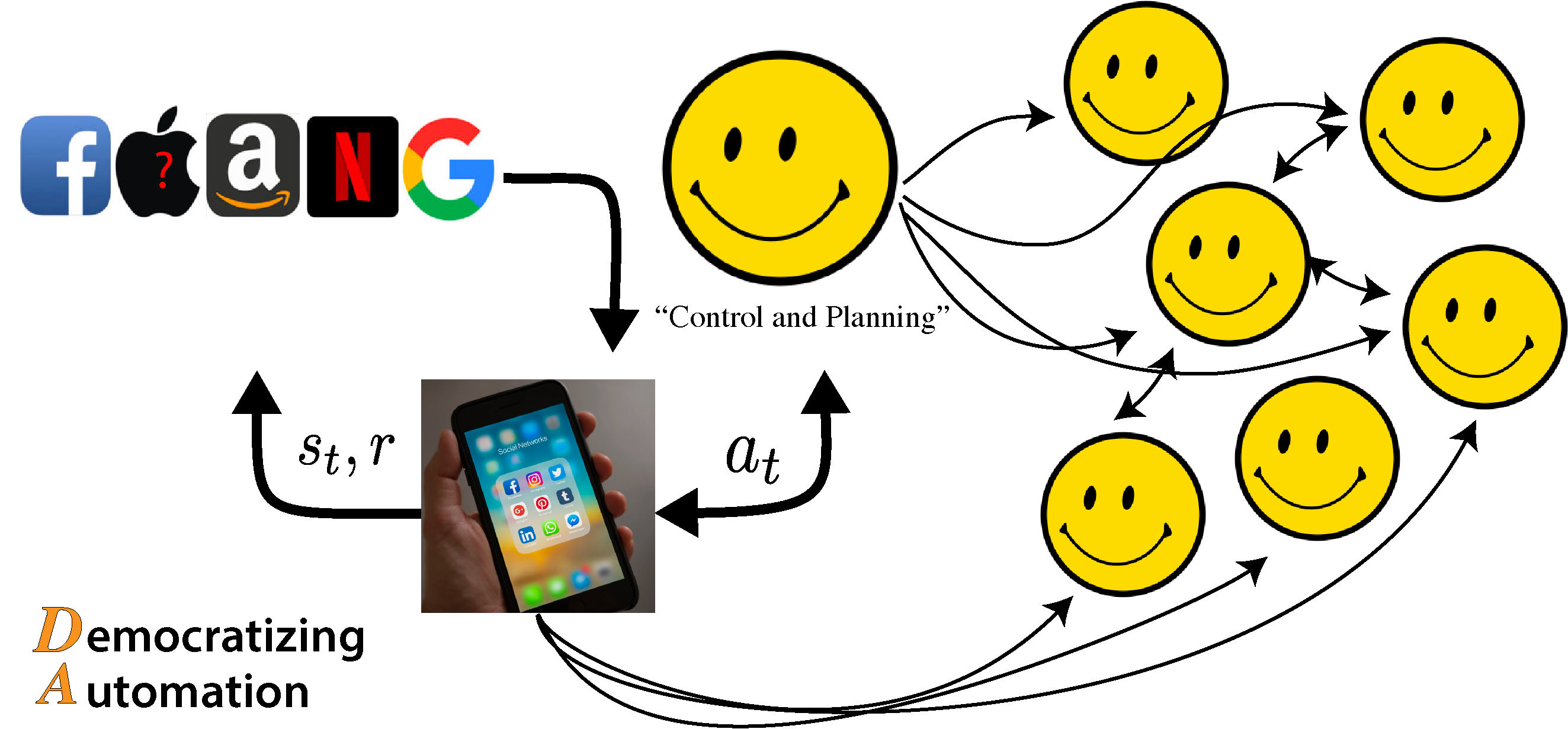
Ultimately, the FAANG companies are going to be logging all of the traffic data (including heuristics towards true human reward that we talked about earlier) and trying to learn how your device should interact with you. It’s a complicated system that has the downstream effect of everyone else you interact within the feedback loop. As an RL researcher, I know the algorithms are fragile, and I do not want that applied to me (but I struggle to remove myself, frequently). The diagram above is most of the point - there is no way that a single entity can design an optimization to “solve” that net.
Let’s talk about the data and modeling. To my knowledge, FAANG is not using RL yet, but they are acquiring a large dataset to potentially do so. The process of going from a large dataset of states, actions, and rewards to a new policy is called batch reinforcement learning (or offline RL). It tries to distill a history of unordered behavior into an optimal policy. My view of the technology companies’ applications is that they are already playing this game, but an RL agent doesn’t determine updates to the recommender system, a team of engineers do. The only case that could be made is that maybe TikTok’s black box has shifted towards an RL algorithm prioritizing viewership. If recommendation systems are going to become a reinforcement learning problem, the ethic solutions need to come ASAP.
Here are resources for readers interested in batch RL course material, offline RL research, and broad challenges of real-world RL.

Follow Up on GPT-3
This is a follow up from my article last week: Automating Code, Twitter's hack(s), a robot named Stretch on the recent OpenAI model GPT3. I wanted to include a couple of points that I have heard repeated for why this is not an economic powerhouse, yet.
From the venture capital perspective, no business that is leveraging this is extremely interesting because there is no competitive advantage. Your advantage would be being the first one to use the tool. It’s not to say people won’t make money off of it, but it is more of a reward for people who are quick on their feet. You don’t own the model - this means that anyone using it is liable to OpenAI clogging their pipe, sorry!
From a practical perspective, a 175Billion parameter model is huge. This is not something that everyone can run 1000s of queries a second on without notable cost (electricity reflected in API costs). There is visible lag in the video demos already (last week I shared this link of a video showing GPT-3 write code). Not only does it imply cost, it implies a barrier to entry. Engineers may turn away from a tool that is inconsistent and difficult to use in favor of consistent progress. Heard the saying that no internet is better than slow internet?
You can read OpenAI’s commitment to making this a safe tool below (clickable link embeds as an image). If you want more material, I suggest you search on Twitter (bizarre that it is all on that platform)


The tangentially related
The best of what I have found and been forwarded this week. Mostly forward-looking, sometimes current events, always good value per time.
Online reading:
A follow-up on interaction in the machine learning twitter community on fairness, data-bias, and if there is algorithm bias (yes there is).
A research-lab “capable” robot from Kuka (a big robotics supplier, at least in research). Let’s be honest, it looks awesome and probably will work in 5 labs, but in 5 years I want one.
A product that lets you record a preset amount of video of yourself and use deepfakes to produce more. I think there are interesting applications in education, where you can have a tutor read any script they want. Very individualized, and the instructor only has to write out content, not speak.
All of Garmin’s apps, production, and website were (maybe still are) from a ransomware attack. Not a good look that you can’t sync your run to your phone without external servers.
Books:
Superintelligence - Nick Bostrom. Thinking about the potential types of superintelligence is fun. Machine intelligence is the starter, but there’s also biological emulation (simulated brains), network superintelligence (if there were 10x humans?), brain-machine superintelligence, and more. Many paths lead to dangerous ground.
Listen or watch:
The Portal - Eric Weinstein with Andrew Marantz (writer, New Yorker), on internet culture, wokeness, privilege, and more.
Making Sense - Sam Harris with Robert Plomin. On genetics and their effect on us as individual genetics. The more I learn about genetics, the more I realize what we have is mostly luck. I love listening, but think in a couple of years when we have polygenetic scores I will need to remove myself from most of the conversation (like discussions on free will, life in a simulation).
Hopefully, you find some of this interesting and fun. You can find more about the author here. Forwarded this? Subscribe here. It helps me a lot to forward this to interested parties, are Tweet at me @natolambert. I write to learn and converse.